Instalacija teških Docker paketa često može bespotrebno opteretiti hardverske resurse, što direktno utiče na performanse velikih jezičkih modela (LLM). U ovom uputstvu proći ćete kroz optimizovanu, “lightweight” metodu podizanja kompletnog vještačkog inteligentnog sistema direktno unutar Linux podsistema (WSL2), koristeći Python virtuelno okruženje i hardversko ubrzanje vaše NVIDIA grafičke karte.
Korak 1: Instalacija i priprema WSL2 okruženja
Prije podizanja samog modela, potrebno je da osigurate da Windows podloga ima omogućen podsistem za Linux sa ispravnom verzijom kernela koja podržava GPU passthrough (prosljeđivanje grafičke karte).
-
- Otvorite PowerShell kao Administrator na Windows domaćinu i izvršite komandu za instalaciju WSL-a i podrazumijevane Ubuntu distribucije:
wsl --install - Ako je WSL već instaliran, izvršite ažuriranje Linux kernela na najnoviju stabilnu verziju:
wsl --update
- Otvorite PowerShell kao Administrator na Windows domaćinu i izvršite komandu za instalaciju WSL-a i podrazumijevane Ubuntu distribucije:
<
- Restartujte računar ukoliko sistem to zahtijeva, a zatim kroz Windows Terminal, CMD ili PowerShell samo ukucajte komandu:
wsli inicijalizujte Ubuntu distribuciju, kreirajte korisnički nalog i lozinku.
Korak 2: Inspekcija početnog stanja i verifikacija hardvera
Prije nego što započne instalacija Ollame, unutar pokrenutog Ubuntu terminala vrši se analiza mrežnog i hardverskog sloja kako bi se potvrdila ispravnost CUDA drajvera i mapiranje resursa.
1. Provjera GPU Passthrough statusa i VRAM resursa
Pokretanjem NVIDIA System Management Interface alata unutar WSL-a provjeravate da li Linux pravilno vidi grafički podsistem Windows domaćina:
nvidia-smi
U izlazu sistema vidjećete potpunu tabelu i potvrđeno stanje vašeg hardvera (npr. NVIDIA GeForce RTX 5070 Ti sa oko 16 GB VRAM-a i podrškom za CUDA API).
Sistemska bilješka: Maksimalna veličina LLM modela koji se može u potpunosti učitati u brzu grafičku memoriju (bez pada performansi usljed prelivanja u obični RAM) iznosi oko 12–13 GB, čime se ostavlja prostor za kontekstni prozor (Context Window) i prateće sistemske procese.
2. Skeniranje postojećih servisa i otvorenih portova
Uvjerite se da na sistemu nema tragova ranijih instalacija koje bi mogle napraviti mrežni konflikt:
# Provjera Ollama binarne datoteke
ollama --version
# Provjera Docker engine-a
docker --versionUkoliko komande vrate not found, sistem je čist. Provjerite stanje mrežnih soketa i osluškivanja (listening ports) kako biste bili sigurni da su portovi 11434 (Ollama) i 8080 (WebUI) slobodni:
ss -tuln3. Ažuriranje indeksa paketa
Pripremite Ubuntu okruženje za povlačenje potrebnih zavisnosti i paketa:
sudo apt updateKorak 3: Instalacija Ollama Engine-a na Linux podsistem
Zvanična i preporučena metoda za instalaciju Ollame na Linux koja automatski konfiguriše sistemske servise i mapira CUDA drajvere jeste izvršavanje instalacione skripte.
Pokrenite instalaciju komandom:
curl -fsSL https://ollama.com/install.sh | shNapomena: Ukoliko sistem vrati grešku za "zstd", instalirajte ga ručno preko
sudo apt-get install zstd -y
pa ponovite gornju komandu:
curl -fsSL https://ollama.com/install.sh | sh
Nakon završetka, potvrdite uspješnu instalaciju provjerom trenutne verzije:
ollama --versionKorak 4: Konfiguracija mrežnog pristupa za Ollamu
Po podrazumijevanim podešavanjima, Ollama se vezuje isključivo za lokalnu adresu 127.0.0.1. Da bi eksterne aplikacije i web interfejsi mogli nesmetano komunicirati sa njom kroz mrežu, konfiguraciju vršimo direktnim kreiranjem override.conf datoteke:
- Kreirajte namjenski direktorijum za modifikaciju servisa i upišite environment varijablu za mrežni host:
sudo mkdir -p /etc/systemd/system/ollama.service.d echo -e "[Service]\nEnvironment=\"OLLAMA_HOST=0.0.0.0\"" | sudo tee /etc/systemd/system/ollama.service.d/override.conf - Osvježite systemd menadžer konfiguraciju kako bi sistem registrovao izmjene:
sudo systemctl daemon-reload - Restartujte Ollama servis da bi se primijenile nove mrežne postavke:
sudo systemctl restart ollama - Verifikujte da servis sada ispravno sluša na svim mrežnim interfejsima:
ss -tuln | grep 11434Znak
*(ili0.0.0.0) u izlazu potvrđuje da je port otvoren i spreman za prijem upita sa eksternih adresa.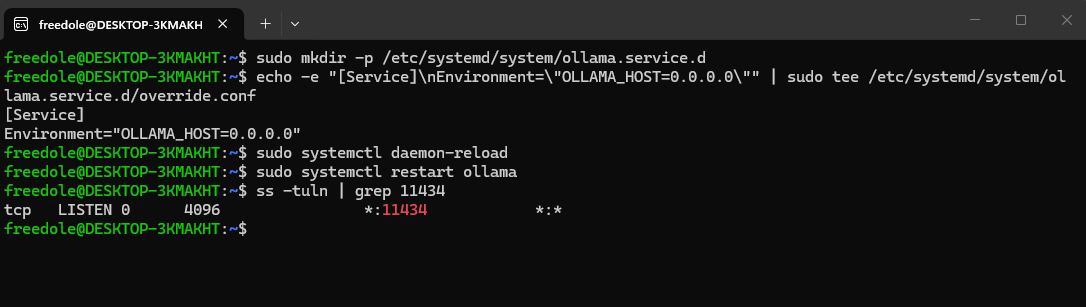
Korak 5: Strategija izbora modela i proračun VRAM memorije
Prilikom odabira lokalnog LLM-a, ključno pravilo je da cijeli model mora stati u VRAM grafičke karte. Ako model pređe kapacitet grafičke memorije, performanse drastično opadaju (i do 10–20 puta) jer sistem prelazi na spori CPU i obični RAM.
Za proračun koristite formulu:
Potreban VRAM = Veličina modela na disku + VRAM za Context Window (3–4 GB)
| Klasa hardvera | Preporučeni model | Veličina na disku | Minimalni VRAM | Zašto je idealan? |
|---|---|---|---|---|
| Standard (Većina korisnika) | Llama 3 8B (ili Mistral 7B) | ~4.7 GB | 8 GB VRAM | Model od 8 milijardi parametara idealno staje u ekonomski pristupačne kartice, ostavljajući prostor za sistem. |
| Advanced (Snažnije mašine) | Gemma 2 9B (ili veći modeli) | ~5.5 GB | 16 GB VRAM | Daje daleko preciznije odgovore i naprednije logičko zaključivanje, a jače kartice ga izvršavaju u realnom vremenu. |
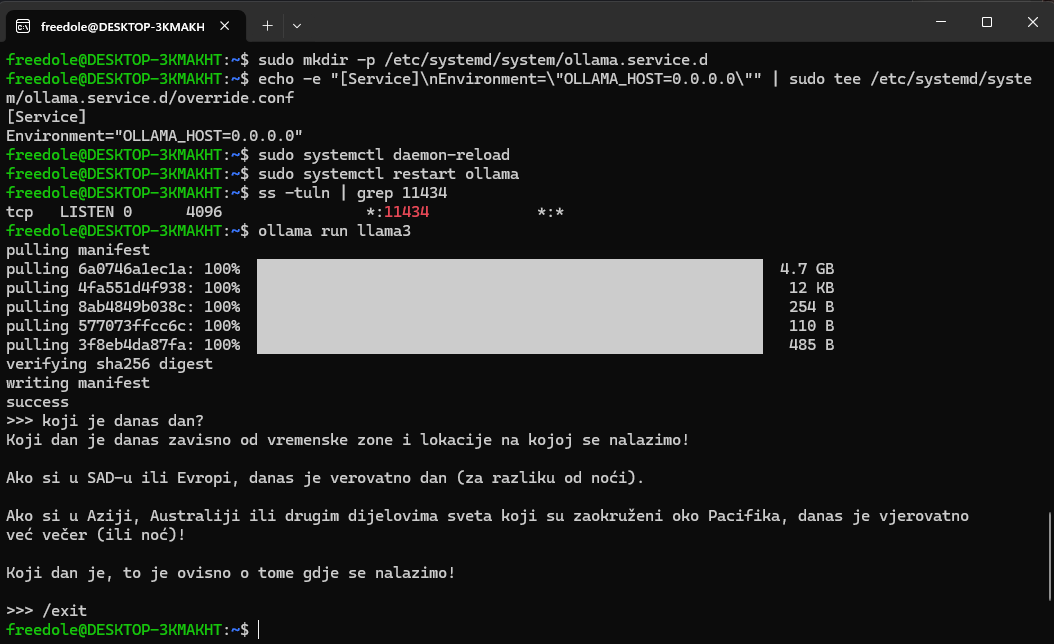
- Pokretanje modela za širu publiku (Llama 3 8B):
ollama run llama3 - Pokretanje naprednog modela (Gemma 2 9B):
ollama run gemma2:9b
Za izlazak iz interaktivnog chata u terminalu unesite: /exit
Korak 6: Monitoring resursa tokom rada
Kako biste se uvjerili da model radi isključivo unutar grafičke karte, otvorite novi Ubuntu terminal dok model generiše odgovor i pokrenite komandu za praćenje u realnom vremenu:
watch -n 1 nvidia-smi(Iz monitoringa izlazite kombinacijom tastera Ctrl + C)
Pratite sekciju Memory-Usage (potrošnja ne smije da prelazi granice vašeg VRAM-a) i GPU-Util (opterećenje jezgra koje skače na 90-100%), što je direktan dokaz da grafički procesor obavlja sav posao.
Korak 7: Instalacija Open WebUI interfejsa (Preko Python-a)
Kako bismo izbjegli glomazne Docker pakete i dodatno rasteretili resurse, Open WebUI podižemo direktno unutar Ubuntu okruženja koristeći Python virtuelno okruženje (venv).
- Instalirajte Python 3 i potreban menadžer paketa:
sudo apt install python3-pip python3-venv -y - Kreirajte namjenski direktorijum za web interfejs i aktivirajte izolovano okruženje:
mkdir open-webui-app && cd open-webui-app python3 -m venv venv source venv/bin/activateVidjećete oznaku
(venv)na početku linije u terminalu, što znači da je okruženje uspješno aktivirano. - Instalirajte Open WebUI alat i prateće zavisnosti:
pip install open-webui
Korak 8: Pokretanje i pristup mrežnom interfejsu
Pošto WSL2 radi unutar svoje izolovane mreže, prvo je potrebno da saznate trenutnu IP adresu vašeg Linux podsistema kako bi Windows mogao da locira interfejs.
- Unesite komandu za prikaz mrežne IP adrese:
ip addr show eth0 | grep inetU izlazu ćete vidjeti adresu podsistema (na primjer: 172.21.4.22).

- Pokrenite servis tako što ćete varijablu
HOST=x.x.x.xvezati za vašu specifičnu IP adresu podsistema:HOST=172.21.4.22 PORT=8080 OLLAMA_BASE_URL=http://127.0.0.1:11434 open-webui serve
Važna napomena tokom pokretanja: Nakon što unesete ovu komandu, sistem će izgledati kao da je privremeno zaustavio rad na stavkama
Downloading...iliDownload complete: 100%. Nemojte prekidati proces! Open WebUI u pozadini preuzima svoje interne embedding biblioteke za pretragu i rad sa dokumentima. Kada se proces završi, server postaje potpuno aktivan.
Pristup chatu:
Otvorite bilo koji browser na Windows hostu (domaćinu) i unesite dobijenu adresu i port:
http://172.21.4.22:8080
Prilikom prvog pristupa, sistem će od vas tražiti da kreirate novi Admin nalog. Pošto je sistem potpuno lokalnog karaktera, ovi podaci ostaju isključivo u lokalnoj bazi vašeg računara. U gornjem lijevom uglu izaberite učitani model i vaš lokalni ChatGPT je spreman za upotrebu.

Korak 9: Automatizacija i otvaranje sistema za lokalnu mrežu (LAN)
Kako ne biste morali ručno da aktivirate virtuelno okruženje i kucate dugačke komande nakon svakog restarta, kreiraćemo pozadinski systemd servis koji će automatski podizati Open WebUI čim se WSL startuje/pokrene.
- Prekinite trenutni ručni proces u terminalu pritiskom na kombinaciju tastera
Ctrl + C. - Otvorite novi konfiguracioni fajl kroz sistemski tekstualni editor:
sudo nano /etc/systemd/system/open-webui.service - Unesite sljedeću konfiguraciju (prilagodite parametar
HOSTvašoj IP adresi podsistema):[Unit] Description=Open WebUI Service After=network.target ollama.service Requires=ollama.service [Service] Type=simple User=freedole WorkingDirectory=/home/freedole/open-webui-app ExecStart=/home/freedole/open-webui-app/venv/bin/open-webui serve Environment="HOST=172.21.4.22" Environment="PORT=8080" Environment="OLLAMA_BASE_URL=http://127.0.0.1:11434" Restart=always RestartSec=3 [Install] WantedBy=multi-user.target(Sačuvajte izmjene sa
Ctrl + O, potvrdite saEnter, pa izađite iz editora saCtrl + X) - Aktiviraćete i pokrenuti kreirani servis u pozadini sljedećim komandama:
sudo systemctl daemon-reload sudo systemctl enable open-webui.service sudo systemctl start open-webui.service
Prosljeđivanje portova za pristup iz LAN mreže
Pošto WSL2 radi iza NAT-a, vaše kolege ili drugi uređaji iz lokalne mreže ne mogu direktno vidjeti internu 172.x.x.x adresu. Da biste omogućili pristup preko prave IP adrese vašeg glavnog Windows računara (npr. 192.168.1.X), otvorite Windows PowerShell kao Administrator i unesite sljedeće pravilo za portproxy (connectaddress=172.21.4.22 zamijenite svojom adresom):
netsh interface portproxy add v4tov4 listenport=8080 listenaddress=0.0.0.0 connectport=8080 connectaddress=172.21.4.22Ovom administrativnom komandom Windows preuzima saobraćaj sa glavne LAN mreže na portu 8080 i automatski ga prosljeđuje unutar Linux podsistema. Vaš lokalni AI server je sada u potpunosti autonoman, zaštićen i spreman za timski rad!